TL;DR Breaches can have real impact on users and impose massive fines on organizations…

Human Eyes Still Essential: Why Code Review Remains Important in the Age of AI Code Generation
The rise of AI-powered code generation tools like GitHub Copilot, Amazon CodeWhisperer, and others has undeniably transformed the software development landscape. They promise unprecedented productivity boosts, automating boilerplate, suggesting entire functions, and accelerating feature delivery. It’s exhilarating to see lines of code appear almost magically. However, beneath this shiny veneer of efficiency lies a complex security challenge. Academic studies are increasingly revealing that while LLMs excel at generating code, they introduce new, scaled problems that make human code review more, not less, critical. The idea that these tools might eventually replace human scrutiny is not only premature but actively dangerous.
Let’s dive into why, drawing on recent academic findings.
The Scaled Problem: Reproducing and Amplifying Insecure Patterns
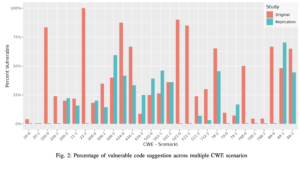
One of the most significant findings from research is that LLMs for code generation, being trained on vast repositories of existing code (much of it from public sources like GitHub), learn and then reproduce common security vulnerabilities. It’s the “garbage in, garbage out” principle on a massive scale. As pointed out in study by Majdinasab, Vahid, et al. titled: “Assessing the security of github copilot’s generated code-a targeted replication study.” (in 2024 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2024). Study shows that a substantial portion of AI-generated code snippets can contain exploitable security flaws. The code generation frameworks covered in this paper were Github’s Code Pilot and showed that evaluated version produced approximately 36.54% of this code snippets with vulnerabilities, which improved to 27.25% in the following version. The study is uses a very insightful method to determine the “safety” of the code. The samples were prompts not to generate code but to fix vulnerabilities. So we’re essentially assessing how bad its “patching ability” is which is great because it integrates a very common use case of LLMs: lazy developers trying to fix their code as quickly as possible. The researchers use the Common Weakness Enumeration to sample some vulnerabilities, stuff like: CWE-798 Hardcoded creds, CWE-20 Improper Input validation, so we’re talking pretty important stuff. One scary take away was that 50% of the vulnerable code suggestions werem suggestions, that cause: CWE-306 Missing Authentication for Critical Function.
The Memorization Problem: Unintentional Disclosure of Sensitive Data
Perhaps on of the most insidious security risk, directly addressed by studies like Rabin, M. et al.’s 2025 “Malicious and Unintentional Disclosure Risks in Large Language Models for Code Generation,” is the problem of memorization. LLMs have been shown to store and, under certain conditions, reproduce exact or near-exact sequences from their training data. This isn’t just about code; it’s about secrets. If the training data included public code repositories that contained accidental commits of API keys, database credentials, or proprietary algorithms, the LLM can memorize and potentially disclose these sensitive tokens to any user who crafts the right prompt. The study evaluates The Open Language Model trained on the Dolma dataset. Imagine asking for a code snippet to connect to a specific service, and the LLM, through memorization, accidentally suggests a line containing a real, live API key from its training data. This is a direct information leak, a critical security breach that bypasses traditional security controls. Human code reviewers are the last line of defense against such unintentional disclosures, tasked with spotting hardcoded secrets or sensitive information that AI might inadvertently cough up.
So if you’re thinking of blindly trusting what an LLM tells you when you’re trying to patch your code please don’t. Especially for critical code make sure a human validates fixes.
The Verdict: Human Code Review is More Vital Than Ever
Code generation tools are powerful allies for productivity, but they are not infallible. They learn from the past, inheriting vulnerabilities and potentially memorizing secrets. They lack the contextual security awareness and critical judgment that human developers possess.
Therefore, the role of human code review has has transformed, one would expect AI to be able to just avoid vulnerabilites we forget it’s just a collection of autocompleted snippets trained on random repos from Github. A good philosophy is to treat AI-generated code as if it were written by a junior developer: probably works but probably should verify too. Rigorous human code review, guided by security best practices and an understanding of these new AI-driven risks, is the essential safeguard against the scaled problems of vulnerability propagation, sensitive data disclosure, and the overwhelming “slop” that can undermine our security posture.
Embrace AI for productivity, but never surrender your human vigilance.
Reading an References
- Malicious and Unintentional Disclosure Risks in Large Language Models for Code Generation – https://arxiv.org/pdf/2503.22760?
- Your Code Secret Belongs to Me: Neural Code Completion Tools Can Memorize Hard-Coded Credentials – https://arxiv.org/pdf/2309.07639
- Eliminating Backdoors in Neural Code Models for Secure Code Understanding – https://dl.acm.org/doi/pdf/10.1145/3715782
- Hey, Your Secrets Leaked! Detecting and Characterizing Secret Leakage in the Wild – https://kee1ongz.github.io/paper/sp25-secret.pdf
Related Posts


